


Heritability of cognitive abilities as measured by mental chronometric tasks: A meta-analysis
Beaujean, A. A. (2005 ). Heritability of cognitive abilities as measured by mental chronometric tasks: A meta-analysis. Intelligence, 33(2), 187-201. doi: 10.1016/j.intell.2004.08.001
Abstract
The purpose of this study is to meta-analyze the published studies that measure the performance differences in mental chronometric tasks using a behavioral genetic research design. Because chronometric tasks are so simple, individual differences in the time it takes to complete them are largely due to underlying biological and physiological mechanisms. The publications that come from these studies show trends, but they also show much heterogeneity, which makes it difficult to draw clear conclusions. Statistically integrating them through meta-analysis is a way to provide a clearer, more comprehensive picture of the magnitude of genetic influence involved in mental processing speed. Analyses from this study show that heritability is somewhat dependent on task difficulty, with performance on more complex tasks having a higher heritability than less difficult tasks. Implications of this study are twofold: (a) mental processing speed is partially heritable (h² estimates from .298 to .521); and (b) as chronometric task complexity increases, so does the heritability.
1. Introduction
The choice of instrumentation can be a problem when trying to discern the heritability of cognitive abilities. The traditional psychometric approach uses tasks whose outcomes are due to both learned and unlearned (i.e., biological) elements (Kranzler, 1993). Jensen (1987) writes that successful completion of a psychometric task involves three distinct components: (a) basic psychological processing, (b) task-relevant knowledge, and (c) a program/strategy. Consequently, the correlation between two given psychometric tasks could be the result of any combination of the three components.
Fortunately, there are other ways to measure cognitive ability besides using psychometric tasks. One is by using mental chronometric tasks, which assess an individual’s reaction time (RT) to a range of very simple tasks (i.e., those who complete the tasks do so with close to 100% accuracy). Mental chronometry has a rich history in psychology that other authors have documented extensively (e.g., Deary, 2000; Eysenck, 1987; Jensen, 1985, 1998). The preponderance of the research in this field shows that the tasks do, in part, measure cognitive ability because of their substantial loadings on a general cognitive ability factor ( g)-loadings that are sometimes as large as many traditional psychometric tests (Carroll, 1993; Jensen, 1998).
A feature of chronometric tasks that makes them unique from their psychometric counterparts is that they mainly reflect individual differences in basic information-processing variables (e.g., stimulus apprehension, stimulus discrimination), and are negligibly influenced by task knowledge, strategy, or other typical environmental variables (e.g., school effectiveness, teacher efficacy, socioeconomic status) that can influence scores on psychometric tests (Jensen, 1998). Consequently, using chronometric tasks in a behavioral genetic research design would allow for an analysis of the determination of the proportion of variance in the information-processing component of cognitive abilities due to genetic factors.
Over the past 20 years, researchers have used chronometric tasks in behavioral genetic research designs (for a review, see Spinath & Borkenau, 2000; for a list of studies, see Table 1), and while these studies show trends, there is significant heterogeneity in results (i.e., a substantial difference in effect sizes across tasks), which makes it difficult to draw clear conclusions (for effect sizes, see Table 2). More specifically, heterogeneity across studies suggests that there is more than one distinct subpopulation in the articles studied (Hedges & Olkin, 1985). Consequently, it appears that a meta-analysis would be useful because it not only allows for statistical integration of the studies, but also allows for a statistical model incorporating effect size heterogeneity (i.e., splitting the sample up by variables common to all studies).
2. Methods
2.1. Selection of studies
Selection of studies for this meta-analysis began with a computerized search of the PsychINFO and ERIC databases for studies using the following key identifiers: mental chronometry, intelligence, twin, behavioral genetic, heredity, and reaction time. Additional studies were obtained by reviewing the reference sections of articles identified in the electronic searches. The procedures described yielded 12 studies [all being monozygotic (MZ) and dizygotic (DZ) twin-comparison studies] and 138 total effect sizes (Pearson product–moment and intraclass correlations). Most studies reported multiple outcomes for the same group of individuals. Tables 1 and 2 list the studies gathered from the literature search.
Three studies (Ho, Baker, & Decker, 1988; Petrill, Luo, Thompson, & Detterman, 1996; Petrill, Thompson, & Detterman, 1995) were excluded from the meta-analysis because effect sizes were not reported and/or because they did not report enough information to calculate the effect sizes. Consequently, nine articles met the inclusion criteria, which means the sample consists of 2405 participants in 18 MZ/DZ groups.
2.2. Combining correlations
2.2.1. Nonindependent samples
Of the useable articles, most authors used more that one chronometric task. For this analysis, initially all correlations within a given study were averaged (i.e., arithmetic mean) together so each study would give a single MZ and a DZ correlation. [1] Once a correlation was found for the twin pairs in each study, it was transformed to Fisher’s (1928) z.
[1] Some given correlations in a study given were discarded (e.g., the “general speed factor” in Vernon, 1989) because they were only amalgams of the given study’s tasks.
2.2.2. Testing homogeneity of correlations across studies
Durlak (1995) and Hedges and Olkin (1985) write that it is important to check for homogeneity in the distribution of effect sizes for the group of studies. The Q statistic tells whether a group of studies is homogenous (e.g., from the same population) and, consequently, if analysis of group mean effects is warranted. Hedges and Olkin elaborate:
a test of the hypothesis of homogeneity of the population of correlations is to reject the hypothesis if the statistic Q = ∑ki=1 (ni-3)(zi-zt)², ...exceeds a critical value from the chi-square distribution with k-1 degrees of freedom [where k is the number of studies] (p. 235).
If the test fails (i.e., the samples are heterogeneous), Durlak (1995) suggests subdividing the studies to achieve homogeneity within groups.
2.3. Model fitting analysis
The studies’ unweighted effect sizes were analyzed using the model-fitting program Mx (Neale, Boker, Xie, & Maes, 2002). Model fitting is used to help estimate parameters (e.g., shared environment, nonadditive genetic) by evaluating different values for a given parameter and seeing how close those different values reproduce the known quantities (i.e., correlations).
There are many different ways to assess a model’s fit, two of which are the chi-square (χ²) and Akaike’s Information Criterion (AIC). The χ² evaluates the magnitude of discrepancies between expected and observed values by comparing how likely the observed data are under a given model. One can test the χ² for statistical significance, with nonsignifigant results meaning that the observed and expected values do not significantly deviate from each other. A problem in using the chi-square analysis is that it is dependent on the n of a study, and studies that have large sample sizes will often have significant chi-square values although the difference between the observed and predicted values is actually very small (Loehlin, 1998). Consequently, this study will employ chi-square values only in assessing change in model fit (Δχ²), which, by comparing chi-square values between nested models, allows for a test of parameter significance (Loehlin, 1998).
In addition to chi-square values, Akaike’s Information Criterion (AIC) can also be used to compare models. AIC is calculated by the following formula:
AIC = χ² + 2q
where q=number of unknown parameters to solve.
It is a badness of fit indicator, with low values indicating a good fit (Akaike, 1987; cf. Loehlin, 1998).
2.3.1. Hypotheses testing in model fitting
In model fitting twin data, one is testing the following hypotheses (Neale & Maes, 2002, p. 103–104; cf. Purcell, 2001): (a) covariations are equal (null model: e=a=c=d); (b) resemblance is due to additive genetic, shared environmental, dominant genetic, and unique environmental affects (“ACDE” model: a>0, c>0, d>0, e>0); (c) resemblance is due to additive genetic, dominant genetic, and unique environmental affects (“ADE” mode: a>0, d>0, e>0, c=0); (d) resemblance is due to additive genetic, shared environmental, and unique environmental effects (“ACE” model: a>0, c>0, e>0, d=0); (e) resemblance is only due to additive genetic effects (“AE” model: a>0, e>0, c=d=0); and (f) family resemblance is due only to the shared environment (“CE” model: c>0, e>0, a=d=0). [2] For a graphical representation of the structural model, see Fig. 1.

[2] None of the models exclude within family variance (e) because this would mean there are perfect MZ twin correlations (r=1). This is bad in two ways. First, MZ correlations in real life are never 1. Second, mathematically, predicting perfect MZ correlations would generate a singular expected covariance matrix, which cannot be inverted, and subsequently a maximum-likelihood fit function could not be estimated (Neale & Maes, 2002). Additionally, random measurement error is modeled as a nonshared environmental effect, and removing it would constitute a model with no measurement error (Purcell, 2001).
3. Results
3.1. Testing homogeneity of correlations across all studies
For the MZ correlations, Hedges and Olkin’s (1985) Q=25.54 (df=8, p<.05). For the DZ correlations, Q=14.92 (df=8, p>.05). Consequently, it appears as is if homogeneity can be rejected for MZ twins, but not necessarily for the DZ twins.
Durlak (1995) suggests that if the homogeneity hypothesis is rejected, subdivide the samples and reassess homogeneity on the subsamples. Jensen (1992) writes that scores on mental chronometric tasks should differ depending on their complexity (i.e., the size of their loading on a g-factor). Consequently, if the articles reported task difficulty (as an indicator of complexity), the tasks were subdivided into two categories: easy and difficult. If an article did not give some index of task difficulty, the author placed the tasks in one of the two categories based on other information given in the each study (see Table 2 for difficulty ratings). [3] If the study included both easy and difficult tasks, the tasks were averaged within the category they were placed.
One study (Baker, Vernon, & Ho, 1991) was discarded because the authors reported only correlations on a factor extracted from all the given chronometric tasks. This left only eight studies for the subsequent analyses, but not every study included both hard and easy tasks. In total, there were seven studies with chronometric tasks classified as difficult and six studies with tasks classified as easy.
When the chronometric tasks were split along levels of perceived difficulty, the Q values were: (a) MZ, easy: 22.4 (df=6, p<.05); (b) MZ, hard: 8.21 (df=5, p>.05); (c) DZ, easy: 11.55 (df=6, p>.05); and (d) DZ, hard: 18.6 (df=5, p<.05). This indicates that for the MZ twins doing the difficult tasks and the DZ twins doing the easy tasks, the results are homogenous; for the other two sets of correlations (i.e., MZ twins doing easy tasks and DZ twins doing difficult tasks), another subdivision might be appropriate. Unfortunately, the articles did not provide enough systematic information on other variables (e.g., sex, race), so another theoretical subdivision cannot be accomplished. [4] Consequently, heritability analyses were run using only this single division of effect sizes. [5]
[3] If the study did not give some empirical indication of task difficulty (which most studies did not), the author rated them based on his own knowledge of tasks - giving difficult rating to those tasks that took more bits of information to process. For some tasks (e.g., slope and intercept of the Sternberg Memory Search), the rating was based solely on the description in the original study that the author(s) gave of the task. Admittedly, the rating is somewhat arbitrary in these cases, and, as indicated in this article’s Suggestions for Future Studies, it is hoped this problem will be remedied in future chronometric research.
[4] Hedges and Olkin (1985) offer a statistical method for separating groups based on their z-transformed effect sizes (i.e., clustering), but because the authors of the studies used did not give enough categorical information about their samples, the resulting clusters could only be defined empirically (and not theoretically), which would magnify the effect of sampling error. Consequently, clustering was not used.
[5] Not being able to further subdivide the studies is unfortunate because, as evidenced in Table 2, there is wide fluctuation in the pattern of correlations. Most likely, this is due to the differences in task difficulties and variance in the ages of the participants, but this will have to be determined in future chronometric research.
3.2. Analysis of correlations split via task difficulty
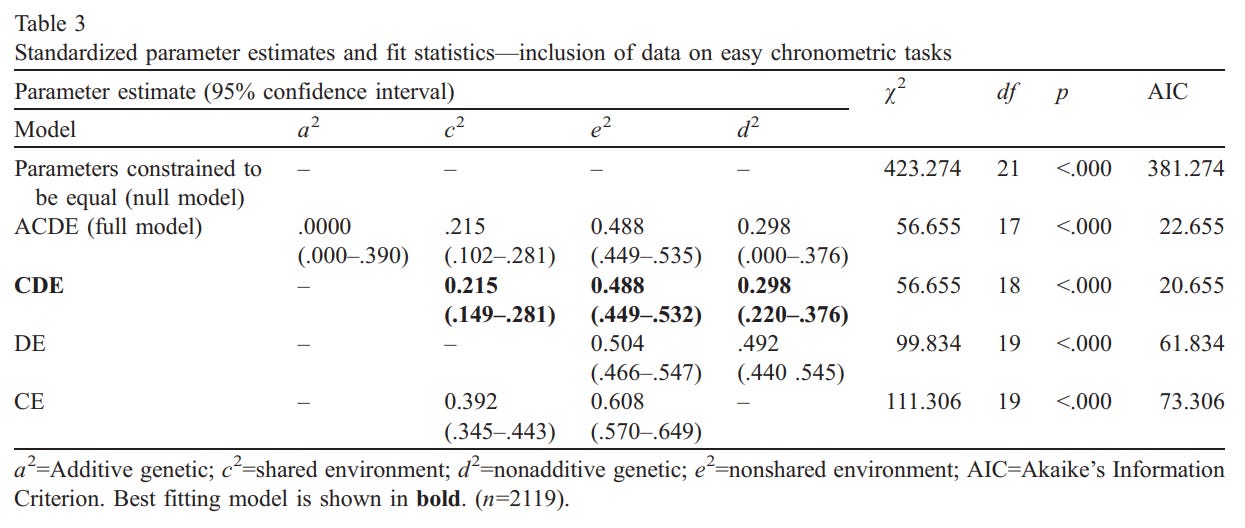
Tables 3 and 4 show the results from model fitting analyses, splitting the tasks via difficulty. All tested models fit better than the null model. Table 3 contains the results of analyses from the samples meeting the easy task inclusion criteria (n=7 articles, 14 MZ/DZ groups, 2119 participants). Using the chi-square difference test, the CDE model was compared to the ACDE model; it was not significantly different (Δχ²=0, df=1, p>.05), but it was more parsimonious, so it was kept. When the DE and CE models were compared to CDE model, both were significantly different (Δχ²=43.179, df=1, p<.05, and Δχ²=54.651, df=1, p<.05, respectively), and thus were rejected as alternative models. This CDE model was confirmed as the best fitting model by its AIC value (20.655), which was the lowest of all fitted models. The CDE model produced a heritability coefficient of .298, with a 95% confidence interval ranging from .220 to .376.

Table 4 contains the results of analyses of the samples meeting the difficult task inclusion criteria (n=6 articles, 12 MZ/DZ groups, 1481 participants). Using the chi-square difference test, the CDE model was compared to the ACDE model, and was significantly different (Δχ²=34.225, df=1, p<.05). Next, the ACE model was compared to the full model and it, too, was significantly different (Δχ²=4.555, df=1, p<.05). Consequently, the ACDE model was kept because it fit the data the best. This was confirmed by the ACDE model having the lowest AIC value (43.862) of all fitted models. The ACDE model produced a heritability coefficient of .521, with a 95% confidence interval ranging from to .411 to .624.
4. Conclusion
4.1. Overview of the results
The purpose of the current meta-analysis was to statistically integrate the published studies that use mental chronometric tasks in a behavioral genetic research design, and, subsequently, to provide a clearer understanding of the magnitude of genetic influences involved in the processing component of cognitive ability. To that end, a major contribution of this analysis is a more accurate understanding of how much of the variance in chronometric task performance is heritable.
When tested for homogeneity, the chronometric tasks’ effect sizes in the studied articles showed heterogeneity, so they were divided into either easy or difficult categories. For the easy tasks, the CDE model fit the best, which meant there were nonadditive genetic (d²=.298), nonshared environmental (e²=.488), and shared environmental (c²=.215) influences. This model gives a heritability coefficient of .298.
For the difficult tasks, the ACDE model fit the data the best, which means there were four significant parameters: additive genetic (a²=.189), nonadditive genetic (d²=.332), nonshared environmental (e²=.309), and shared environmental (c²=.168). This model gives a heritability coefficient of .521.
4.1.1. A note on the type of heritability
An unexpected finding from this study is that the majority of the genetic variance is nonadditive. This is due in large part to the fact that there are negative DZ correlations in the three of the studies (McGue & Bouchard, 1989; McGue, Bouchard, Lukken, & Feuer, 1984; Neubauer, Spinath, Riemann, Anleitner, & Borkenau, 2000). [6] When there are negative correlations in the DZ twin pairs, it indicates that either there is nonadditive genetic variance or there is a contrast effect (i.e., behavior in one twin leads to opposite behavior in the cotwin; Rietveld, Posthuma, Dolan, & Boomsma, 2003). To empirically distinguish between the two, one needs to examine (co)variance structures, which were not systematically reported in the studies used for this meta-analysis. As there is not a literature base indicating that there might be interaction between twins concerning their reaction times, it seems plausible that the negative correlations are due to nonadditive genetic variance, but this will need systematic investigation in future studies. [7]
Much of the behavior genetic research that investigates cognitive ability has found the heritability to be made up of largely additive effects, and it is unclear why it is different in this study. It could be that the heterogeneity in effect sizes (i.e., the significant Q statistics) overinflated the e² parameter (which contains both nonshared environmental influence and error) and, consequently, decreased the a² parameter. If this is the case, it could be that the additive genetic effects are as great or greater than the nonadditive effects, but the inflated error suppressed this relationship.
An alternative hypothesis would be to follow Fisher’s (1930) Fundamental Theorem. Fisher suggests that traits subjected to constant natural selection will exhibit less-and-less additive variance and the nonadditive component will come to dominate the genetic variance component in a behavioral genetic analysis. If, as others have written, the trait that the various chronometric tasks have in common (i.e., information-processing speed) is a measure of cognitive ability (Jensen, 1998) and cognitive ability is very important to life outcomes (Gottfredson, 1997), then it would make sense that this fitness character would be selected over time. This effect may not be evident in other behavior genetic studies, not because the effect is absent, but because the studies are underpowered (Martin, Eaves, Kearsey, & Davies, 1978) and it takes a study with power of a meta-analysis to make this particular effect evident. More research is needed before there is a more definite answer.
[6] When the meta-analysis was rerun without including the negative correlations, the model for easy tasks did not change, nor did the parameter estimates significantly differ, but for the difficult tasks, the ACE now model fit the best, which gave the following parameter estimates: a²=.582, c²=.101, e²=.321.
[7] There are two types of nonadditive genetic variance: dominance and epistasis. Dominance is evident when a heterozygote (i.e., one who caries different alleles at a locus) is not exactly intermediate in a given trait between two individuals who have the same two alleles at a single locus (i.e., homozygotes). One can conceptualize it as an interaction between alleles at the same locus (Neale & Maes, 2002). Epistasis is similar to dominance, except that it is concerned with interaction at multiple loci. If either effect is present in the measured trait, it will show itself in the d² parameter.
4.2. Comparison of results to other studies
4.2.1. Twin studies using mental chronometric tasks, but not included in the meta analysis
Ho et al. (1988) found similar results to this study. For their study, they factor analyzed a group of mental chronometric tasks, and calculated the heritability for the two orthogonal factors (both of which had a .41 correlation with Wechsler Full-Scale IQ scores). They reported heritabilities of .52 and .49. Petrill et al. (1996) found similar heritability results in their study. For their mental chronometric tasks, they used Detterman’s (1990) Cognitive Abilities Test (a specific test battery devised of mental chronometric tasks), which includes both easy and difficult tasks. They found the heritability coefficients for the individual tasks ranged from .46 to .50.
4.2.2. Behavioral genetic studies using psychometric instruments
Devlin, Daniels, and Roeder (1997) did a meta-analysis of behavioral genetic studies and cognitive abilities using psychometric instruments. Their inquiry was little different from the present study (i.e., they were testing the potency of maternal affects on heritability), but they still found a similar heritability coefficient (.48). Similarly, in their textbook on behavioral genetics, Plomin, DeFries, McClearn, and McGuffin (2001) report an average heritability of cognitive ability across many studies (again, using psychometric instruments) of .52 (p. 166).
4.3. Importance of the current study
There are three main results from this study, one of which is confirmatory in nature, and two that add to the body of literature in the study of human cognitive ability. The confirmatory finding is that cognitive ability, at least as measured by chronometric tasks, is partially heritable. This is not a new idea, as Galton (1869) wrote on this over 100 years ago. Moreover, many studies in the 20th century found similar results using various types of instrumentation (for reviews, see Carroll, 1993, chapter 17; Jensen, 1998, chapter 7; Plomin et al., 2001, chapter 9).
The first unique finding is that, as Jensen (1992) suggested, the heritability of performance on mental chronometric tasks does vary as a direct result of their difficulty. There are a few plausible reasons for this, but an information-processing theory (Jensen, 1992, 1998) appears to make the most sense. This theory holds that as the tasks get more complex (i.e., increase in difficulty), more information has to be processed before a response can be made. Consequently, as more information has to be processed, the more biological and neurological variables (e.g., speed, efficiency) play a part in the reaction time; moreover, the more the reaction times depend on variables that have a wide variability across individuals, the more genetics will be involved, which means the heritability will be higher.
Another plausible, and not mutually exclusive, reason is that as tasks increase in their g-loading, their heritability increases. Unfortunately, not enough articles reported the g-loadings for the chronometric tasks to test this empirically. Consequently, this will have to be tested in future meta-analyses.
The second unique finding is the broad heritability coefficients derived from amalgamating multiple mental chronometric studies. This study found that for relatively easy tasks, the broad heritability coefficient was .298, and for the relatively complex tasks, the broad heritability coefficient was .521. These results can serve as a baseline for comparison in future chronometric research.
Third, this study found that for both the easy and difficult tasks, there was more nonadditive genetic variance than additive genetic variance, which is due, in part, to the fact that there are negative phenotypic correlations in some studies. This relatively large d² coefficient is not common among many intelligence or chronometric studies, and more research needs to be done to see if this is just an artifact of this particular data set, or if cognitive ability, at least as measured by chronometric tasks, really does follow Fisher’s (1930) Fundamental Theorem.
4.4. Suggestions for future studies
4.4.1. Report effect sizes
In the current meta-analysis, three studies were not used because they did not report the MZ and DZ correlations on the studied tasks. For future meta-analyses in this area, it would be helpful if studies would report these correlations. Preferably, these correlations would be reported for each mental chronometric task, even if they were also reported as correlations on factor scores.
4.4.2. Other moderators
In the current study, only task difficulty could be used as a moderating variable. In future behavioral genetic studies that use mental chronometric tasks, it would be helpful if the authors reported twin correlations divided by age and sex (for an example, see Luciano, Wright, Smith, Geffen, Geffen & Martin, 2001, p. 587). Additionally, to make task difficulty easier to assess, authors should report the tasks’ g-loadings and their mean/median response times.
4.4.3. Standardization of tasks
While many different chronometric tasks are available to use, it would behoove researchers in this area to decide upon a common, standardized set of them to use across research venues. Possible confounding affects can arise when different assessment methods are used across different research projects, which can take away from both generalization and the validity of cross-study combination (e.g., meta-analysis). As a starting place for standardization, Arthur Jensen (personal communication, December 2003) has suggested that all chronometric research laboratories should at least include the followings tasks in their battery: (a) simple reaction-time task; (b) simple choice task (1 bit); and (c) a more complex choice task (4 bits, e.g., Odd-Man Out Task, Frearson & Eysenck, 1986).