
A Further Comment on the Meta-Analytic Jensen Effect on Heritability and Environmentality of Cognitive Tests
I discussed at length the results at Human Varieties. I will simply add some more important comments here. A lot of problems must be highlighted. Although large positive g*h2 and modest negative g*c2 correlations were found, heterogeneity of effect sizes should be taken into account. Limitations of the method of correlated vectors are discussed as well.
But while we could more or less be confident that g*h2 (heritability) is non-trivially positive, and that we could be assert that g*e2 (non-shared environment) is strongly negative with a lot of confidence, we couldn’t be certain that g*c2 (shared environment) is the way it should be in the samples included in the present meta-analysis. The EXCEL file can be accessed here. I computed the Pearson and Spearman correlations as well. As for the latter, those values are often meaningless because most test batteries comprise only a small number of subtests, rendering Spearman correlations too sensitive. Other statistics of interest are displayed as well. Studies in bold are those having more than 6 subtests. Studies that have been highlighted are those that met the inclusion criteria (minimum of 7 subtests and varied content-type test battery).
Initially, the meta-analysis comprises 36 studies (42 data points, or correlations), but finally the sample was reduced to 18 studies (19 data points) due to inclusion criteria. These were : subtest numbers by a minimum of 7, and a test battery more or less representative, that is, not over-represented by only one type of content. As for the latter, I have included even some batteries which in fact are not very representative, but at least more representative than some batteries in which only tests of verbal content were included in the battery. The obvious reason for not including them is that g tends to be more correlated with each other when using a highly varied content-type battery of tests. We need batteries that are representative of diverse aspects of intelligence. Regarding the minimum number of subtests, one would say this is arbitrary, but even Dolan & Hamaker (2001, p. 19) argued that 13 subtests are not large enough. And as I show below, even a subtest number as high as 9 could lead to a very ambiguous result. So, even 7 subtests is just way too low.
When constraining the meta-analysis to 18 studies, we see that the intially high variability in effect sizes for h2 has been greatly reduced while for c2 we still see that its correlation with g-loadings displays no clear pattern at all. Clearly, this could be explained by the higher reliability of h2 vector.
What accounted for the consistency of negative correlations in g*e2 is certainly the very high reliability, of about 0.90 and more. By way of comparison, h2 and especially c2 vector are not highly reliable. h2 had some negative and near zero correlations with each other, while c2 had a lot of negative and near zero correlations with each other. See Wechsler’s data. Of course, a negative or zero reliability coefficient does not exist and is not making any sense. As Dragt (2010, pp. 40-42) and Metzen (2012, pp. 45-48) suggested, we could simply ignore those values when applying the corrections for vector (un)reliability, along with g vector (un)reliability, g-loadings range restriction, deviation from perfect construct validity and eventually sampling error. Metzen (2012, pp. 45-51), Repko (2011, pp. 16-22) te Nijenhuis (2007, pp. 287-288) and Jensen (1998, pp. 380-383) explain the logic behind those corrections.
What has been found to be most problematic is that even when vector reliability of h2 or c2 is quite high (say, about 0.70 or 0.80) the correlation with g can be very different. We can illustrate this problem best by showing the outcome for the Dale (2010) and Olson (2013) studies, not included in the final meta-analytic correlation, due to inclusion criteria.


It is clear from the above that h2 and a2 values are very close, and yet their correlations with g-loadings markedly different. The most likely culprit is the small number of subtests that renders those correlations completely meaningless. Worse has yet to come. The Olson (2013) study shows h2 and a2 correlations with g in opposite directions; negative for the first, positive for the second. The most likely reason must come from Copy and Rapid Naming subtests since these subtests show disparate values in column h2 and a2. How could we resolve this issue ? Simply by increasing (even more) the vector reliability and/or by increasing the number of subtests so that a slight deviation in any values would not affect the observed correlation at all. Finally, increasing the sample sizes could also improve vector reliability. te Nijenhuis (2013, p. 3) showed for instance that g vector reliability increases when sample size increases. This observation could also apply for h2 and c2. Unfortunately, the studies who passed our inclusion criteria had samples comprised between 100 and 500. There was no large sample sizes to make such comparisons.
All this would assume however that h2 and c2 reliability shouldn’t be naturally low or modest. This question is legitimate since the reliability of g-loadings vector is quite large (te Nijenhuis et al., 2007, p. 287) at about 0.86 according to Jensen (1998, p. 383). So the question is why, despite having used Wechsler scales as well for estimating the reliability of h2 and c2, I arrived at a very low or modest value ? Perhaps it’s the way it should be : h2 and c2 had naturally low reliability and few things could be done to correct for this defect. If that is the case, as far as g*c2 is concerned, a Jensen effect on c2 should not be tested with MCV because the obtained outcome, whatever it looks like, would necessarily be meaningless.
The effect of age could be taken into account as well. Given the Wechsler’s data I collected, 6 modest samples for WISC and 5 modest samples for WAIS, it appears that h2 reliability is much larger in the WAIS, since they lie around 0.65 or 0.70 maybe. WISC reliabilities look terrible in contrast, because more than half of them had near zero reliability or negative reliability, as shown by all the r(h2*h2) combinations possible across studies, and even the h2 vector correlations that are significantly different from zero do not exhibit very high values, apparently lying around 0.65. Normally, such correlations would be seen as good enough but insofar as vector reliability is concerned, I doubt it is enough especially when the number of subtests is so weak (about just 10). As shown by Olson data above, it is not implausible that a high reliability (0.868 for Olson) would lead to very different pattern of correlations. In any case, since we don’t have a large number of large samples to compare the vector reliabilities, broken down by age, we are not certain that there is really an age effect with regard to reliability. But if so, samples of children should be corrected for vector reliability for children samples and samples of adult corrected for vector reliability for adult samples. My doubt is even strengthened by the fact that c2 and e2 reliabilities look virtually the same in the WAIS and WISC. I see no reason why h2 reliability only should be affected by age. Finally and still concerning h2, something curious must be told. Even when h2 reliabilities are negative or near-zero in the WISC, all these independent h2 correlate with WISC g-loadings, except for Owen & Sines which has by far the smallest sample size. The different r(g*h2) lie around 0.35. It’s difficult to make sense of it.
Apart from the number of subtests and sample sizes, one obvious reason for the high c2 unreliability vector is that c2 values had sometimes a large number of zeros, rendering the obtained correlations somewhat meaningless because the sign and magnitude of the correlation depend almost exclusively on 2 or 3 values, instead of, say, 8 or 9. Needless to say, in a case like this, a small deviation in just one number would greatly affect the correlations. The best way to correct for this is to remove measurement errors and to drastically increase the number of subtests for all MCV tests. But this entails another problem since it is known that most current and used IQ tests comprise generally no more than 10 or 13 subtests. We see however that Olson had 9 subtests, which would be surely considered by most researchers as a large enough battery.
Still related somewhat with g*c2 correlations is that a good portion of the studies provided MZT and DZT twins (reared together) which allows the computation of Falconer’s formula for calculating h2, c2 and e2. However, sometimes, h2 values exceed 1 or had been lower than 0. In such cases, the values were replaced by 1 and 0, respectively, because there is no such thing as heritability higher than 1 or lower than zero (i.e., negative). Some researchers did the same thing (e.g., Rushton et al., 2007, supplemental data; Haworth et al., 2009, Table 3). The problem is when we look at c2 vector. When we are left with a lot of negative values, and we replace all of them by zeros, the direction and magnitude of correlation depend almost solely on the very few remaining positive c2 values thus rendering any found outcome somewhat questionable. Any slight deviation in one value would drastically distort the correlations.
Likewise, g vector unreliability might pose a problem for nearly half of the studies because g-loadings were computed using intercorrelation matrices given in the papers. See Rietveld (2000) although not included for an example of this. As te Nijenhuis (2013) said, g-loading vector reliability increases with sample size. We should have used g-loadings taken from books or manuals. This wasn’t possible since most of the batteries were not very good; those papers select the subtests from many different test batteries and combine them to form a new, hybrid battery of selected subtests. Most of these papers were not included in the final meta-analytical correlation.
Also related with the computation of variance components (h2, c2 and e2) is the differences between studies in methods. Some studies give MZ and DZ twin intraclass correlations while also computing the variance components using sophisticated techniques (e.g., latent factor approach, which is supposed to remove measurement errors; see Davis et al., 2009) under multivariate genetic analyses. As far as I can see, those different estimates sometimes had good correlations with each other, sometimes moderate or low. Even when they are highly correlated, we already see above that the correlation between g-loadings and h2 or c2 could differ widely.
All this having been said, here’s a scatterplot of (uncorrected) g*h2 against N. It appears that h2 increases slightly when sample size increases. The same cannot be said for c2 and e2. Anyway, this is most likely due to the two smallest samples which exhibit negative Jensen effects on h2. These two exceptions left, we see that g*h2 values are generally larger than 0.400. Weighting the correlation (scatterplot) by subtest numbers means that we give more weight (i.e., importance) to the studies having more subtests.


Next, I show below the results for meta-analytical correlations. The first table shows the unweighted values, so that N column displays the real number of data points or correlations. The second table has been weighted by sample size (each data point multiplied by its respective sample size). I haven’t corrected for sampling error, using Harmonic N formula although I computed it (see EXCEL) but in any case whether using sample size as such or harmonic N hasn’t changed the weighted meta-analytic correlations.
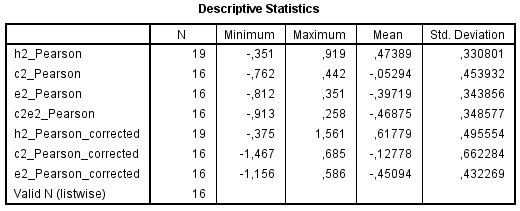
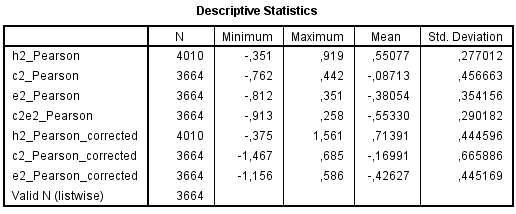
Some correlations could be higher than 1, but te Nijenhuis explained that this situation is not uncommon when applying all these artefact corrections. In such cases, correlations larger than 1 must be interpreted as to say that the ‘true’ correlation is perfect; that is, 1.
I could correct for h2 reliability as well, using my Wechsler data from my earlier post, which could be around 0.50 and 0.70 if we ignore negative values and near-zero values, and given this, the reliability coefficient could be well about 0.60 which gives us r/SQRT(0.60*0.86) where r is the uncorrected (for reliability) correlation and 0.86 the g vector reliability. When applying the additional correction for all individual data points, my meta-analytic correlation (already corrected for all other artefacts) goes up, from 0.727 to 0.938. In other words, h2 reliability makes a huge difference.
The reason why I haven’t corrected the g*c2 for unreliability is because the correlations were too heterogeneous. While we see from the above a meta-analytic correlation of about -0.13 or -0.17, we don’t know with a lot of confidence that g*c2 should be normally negative. The variability in effect sizes, as far as c2 is concerned, is greatly accounted for by c2 vector unreliability. And correction for artefacts would just increase the observed meta-analytic correlations.
Note : I haven’t included Davis et al. (2009) study while having good number of subtests and a more or less varied content-type battery, because the sample size was too large, thus having an extreme leverage on the results, and rendering the individual contribution of all other studies completely worthless. There is even no need to conduct a meta-analysis when the individual contribution of studies can be washed out this way. The exclusion of this sample is legitimate for the meta-analytic value of c2 as well because it changes from -0.165 to +0.352. The positive g*c2 was solely due to the Davis et al. (2009) sample. Also important; the reason why the numbers in the above tables are slightly different from the EXCEL here is because, among other things, I computed Pearson correlations using SPSS by copy pasting the values from my EXCEL spreadsheet to SPSS, while in fact EXCEL has been configured to display only 2 numbers (i.e., rounding) after the dot when the truth is that EXCEL usually display more than 2 numbers (e.g., 10) as this was sometimes the case for g-loadings. This lacked accuracy, although just a little bit. And since the Friedman (2008) study used latent variable approach, which removes measurement errors, I chose the uncorrected g-loadings for the correlation with h2, c2, e2 because of the way these variance components have been computed (squaring the general g-loadings and adding broad g-loadings to the computation of each variance component) to the extent that using corrected g-loadings to correct for subtest reliability could be unnecessary. But this having been corrected, with some misreported numbers, the final result is hopefully virtually unaffected.