


Holes in the Colorism Hypothesis
Introduction. If color-based discrimination becomes more intense at a later age, when darker-skinned individuals face discrimination in the labor market and thus depressing their economic opportunities at every level, for instance, the colorism hypothesis could have argued that IQ measured at earlier ages would not mediate the IQ-outcome relationship measured at a later age because discrimination would have conditioned later success in life.
Stated otherwise, the colorism hypothesis suggests that earlier measured IQ could be a less important predictor than later measured IQ because the (possibly cumulative) negative effect of discrimination would grow over time or because discrimination is marked in adulthood. But even if earlier measured IQ appeared less important than later measured IQ in predicting economic success, it doesn’t knock down the genetic hypothesis, because “the pattern of IQ change over age possesses far less heritability (if any at all). . . .” (Jensen, 1973, pp. 92-93). Even if IQ change over age was due in part to skin tone discrimination, it makes its relationship with g unlikely.
As I argued elsewhere, if the colorism prediction is correct, there must be a negative correlation between darker skin and social outcome, when economic background and/or IQ have been controlled. Controlling for SES is a genetic effect, to the extent that SES has a genetic component (Jensen, 1973, pp. 116-117, 155-156).
So even if we control for family background, IQ, education and all the like, the colorism hypothesis still predicts a relationship between skin color and wage (or education). This is because the color discrimination is all about physical appearance, and nothing more. It posits that because you look black, or because you have negroid traits, you are discriminated against. And this phenomenon occurs at every place, as colorism predicts. If the relationship persists after controlling for SES and IQ, that correlation won’t be enough to draw any conclusion about the arrow of causality however. Further information is needed. For example, the genetic hypothesis may argue that it is due to differences in racial admixture or other characteristics tied to skin color, and that skin color therefore is just a confounding factor. But if the correlation drops to zero, we cannot even begin to speak about causality.
In fact, it is not inconceivable that skin color could be largely mediated through other characteristics. Not long ago, I reviewed a study by Mobius and Rosenblat (2005) showing in an experimental study which reproduces as much as possible the conditions of the labor market that the beauty premium persists even when the visual interaction between the employer and the worker was absent. This effect was partly mediated through oral interaction (telephone), which suggests that attractive people have some oral skills. I have suspected that the reason could be that beautiful people are more intelligent, among other things. If people have a preference for attractive persons, just like they have a preference for light skinned persons, the beauty premium study referred above may help us understand the light skin premium that prevails in the labor market.
If colorism is all about appearance (i.e., skin tone) and nothing more, it would be meaningless to assess the effect of skin color when other confounding factors (e.g., delinquency, admixture, education, parent’s background, and so on) have not been taken into account. One problem with controlling for almost everything is that the sample sizes will be too small. So I will control for just a few variables, the classic ones : education, income, IQ.
Method and variables. I applied the weights for the subsequent analyses (Add Health and NLSY97 data) using SPSS program, because it helps make the result more representative. One problem with weights is that the sample size is inflated. The standard error is considerably reduced, so that the t-statistics increase, and so that the p-values are considerably lowered. I tried to apply the method of scaled weights (Osborne, 2011, p. 3) to restore the original sample size. We need to multiply the weight variable by the original N and divide it by the inflated N for each separate analysis. In other words, if you are going to run 10 regressions, you need to compute 10 scaled weights, one for each analysis. In any case, I found another way to compute the p-values for the weighted results. We just need two things. The original sample size (which can be displayed by running the regression without applying weights) and the coefficient of the partial correlations displayed in the regression table. Using these online calculators (graphpad, danielsoper) or this spreadsheet, we can find the p-values of our independent variables. Sometimes, p-value calculator requires the df and not the n, but the df is just the number of cases minus the number of independent variables. To note, the p-value increases when the sample size decreases. But at a given sample size, the p-value also increases when the coefficient tends to decrease. Of course, this is not to say that the p-value can be thought of as an index of relative importance because it only indicates the evidence of a non-zero association, not the magnitude of the association.
One of the assumptions of the linear regression is that the residuals must be normally distributed, and if not, the dependent variable should be transformed (eg, using log or SQRT). From the IDRE UCLA regression chapter 1, we read :
Some researchers believe that linear regression requires that the outcome (dependent) and predictor variables be normally distributed. We need to clarify this issue. In actuality, it is the residuals that need to be normally distributed. In fact, the residuals need to be normal only for the t-tests to be valid. The estimation of the regression coefficients do not require normally distributed residuals. As we are interested in having valid t-tests, we will investigate issues concerning normality. ... A common cause of non-normally distributed residuals is non-normally distributed outcome and/or predictor variables.
We can look at the P-P plot and the scatterplot of the residuals for testing the assumption of normality. For the P-P plot, if the dots deviate significantly from the reference line, this is a problem. For the scatterplot, we need residuals to be randomly distributed, with no significant heteroscedasticity and the absence of a non-linear relationship between the standardized residual and the standardized predicted value, and so the spread of residuals should be more or less the same at each point along the predictor (indep.) variable. The consequences of violating the assumption of homoscedasticity are serious because the standard errors associated with the standardized betas may be biased (downward) and thus the result is shown to be statistically significant when it might be in fact not. With a few exceptions, the assumption of normality has been met. I dealt with these few exceptions below.
We also need to look at the outliers, and see whether or not they could distort the results, especially when the points exceed the 3 standard deviations around the mean. But finding an outlier does not mean that it has a significant influence on the regression results. Unfortunately, the use of weights also distorts the values of Cook’s Distance and other statistics used to assess the influence of individual cases (they have only zeros in their decimals), so that they cannot be taken at face value. So we need to re-run the regression without weights or apply the method of scaled weights. Of course, outliers provide useful information, and it does not make sense to remove them without any reasons. Nevertheless, I will show the results with and without the influential outliers. Fortunately, with one exception, the results appear more or less the same.
For doing this, we need to ‘save’ the Mahalanobis, Cook’s Distance, Leverage Values, Standardized DfBeta(s), Standardized DfFit, and Covariance Ratio (CVR) statistics, when we run the regression analysis (without weights, or with scaled weights). This will generate eight new variables. I choose the standardized versions of DfBeta and DfFit for reasons discussed by Field (2009, p. 219) regarding the problem of the units of measurement of the outcome. Then, we will go to Analyze, Reports, Case Summaries, and put our eight variables (also check “Show case numbers”), and run the table.
If individual cases have little influence, then :
The Cook’s D statistics would be lower than 1 (although some said not larger than 4/n, where n is the sample size),
The Mahalanobis D statistics would not display any value greater than 25 (for greater sample, e.g., 500) or even 15 (for smaller sample, e.g., 100),
The Centered Leverage Value will not display any value two or three times greater than (k+1)/n where k is the number of predictor (indep.) variables,
The DfFit values should not be larger than 2*SQRT(k/n),
The DfBeta values should not be higher than 1, although others said not higher than 2/SQRT(n),
The CVR should fall between the values of CVRi > 1 + [3(k + 1)/n] and CVRi < 1 - [3(k + 1)/n].
See Linear Regression chapter, p. 435, for further details. Sometimes, I note that in the Case Summaries table, the values do meet the above criteria even if the Cook’s Distance value is fine. Even if a few values fall outside the limits (eg, for DfFit or CVR statistics), that is of no concern since the Cook’s D values are just below 1, and that when a case shows a high value in Mahalanobis, CVR, or else, it generally shows a high value of Cook’s D. Note that “the use of Cook’s Distance alone is usually sufficient to measure influence” (Weinberg & Abramowitz, 2008, p. 418). Here is what Stevens (2002), quoted in Field (2009, p. 219), says :
If a point is a significant outlier on Y, but its Cook’s distance is < 1, there is no real need to delete that point since it does not have a large effect on the regression analysis. However, one should still be interested in studying such points further to understand why they did not fit the model. (p. 135)
Also, I will not put much faith in the Kolmogorov-Smirnov and the Shapiro-Wilk tests. They are very sensitive to sample size (Field, 2009, pp. 148, 788). This increases the probability of rejecting the null hypothesis (eg, p-value less than 0.05) that the distribution is normally distributed, while for testing the normality of the residuals, we want a p-value at least higher than 0.05, not less.
In large samples these tests can be significant even when the scores are only slightly different from a normal distribution. Therefore, they should always be interpreted in conjunction with histograms, P–P or Q–Q plots, and the values of skew and kurtosis.
The variables and the syntax I used for the Add Health analysis are listed here. For NLSY97, go here. I explained in an earlier article how to use Add Health, NLSY97 and SPSS. The skin color variable in Add Health is a 5 point scale variable, where 1 = black, 2 = dark brown, 3 = medium brown, 4 = light brown, 5 = white. And the skin color variable in the NLSY97 is measured on a scale of 1 (lightest) to 10 (darkest) with a color card as reference. So when the AddH skin color correlates positively with social outcome, this means that lighter skinned individuals have higher economic success. With the NLSY skin color variable, this would mean that darker skinned have higher success.
Results from regression analyses. Because colorism predicts a positive correlation between light skin and social outcome, regardless of skills and other background characteristics, the purpose is to control for economic background as well as IQ, and see what happens to that correlation.
Add Health Analysis 1. Below, we see that PPVTw1 is clearly a better predictor of educational attainment (N=808). But we will see, in Analysis 3, that this is mostly driven by the black females respondents, and this poses a question regarding its generalizability. To note, PPVT wave-1 (mean age of respondents = 16) and wave-3 (mean age of respondents = 22) are not strongly correlated among blacks (weighted correlations : Pearson r = +0.513, Spearman rho = +0.619). This can explain to some extent why there is no substantial mediation.
")
Add Health Analysis 2. Here, I look at the relationship between skin color and personal earnings (Wave 4) when controlling for the effect of verbal IQ and parental income. Among black men (N=258), the correlation is very low, falling from 0.070 to 0.013. Curiously enough, the effect of PPVTw1 is near zero. However, this figure may not to be taken at face value, since the P-P plot of residuals shows a significant deviation from normality, as shown below.

One possible explanation is that the dependent variable, personal earnings, is not normally distributed (we can look at this with the histogram). To correct for this, I used the square root transformation rather than the log transformation (which had made things even worse). The picture looks like this :

This is really an improvement, and now the coefficient table looks like this :

")
Skin color and PPVTw1 account for nothing. PPVTw3 and education level are the most important predictors of personal earnings.
For black women (N=362), a similar pattern can be seen. The color-earnings correlation falls from 0.063 to -0.003. But the P-P plot does not follow the reference line very closely although the deviations were not too serious. So I used the variable sqrtEARNINGS instead of H4EC2. There is a slight improvement. The result appears as follows :

")
The color-earnings correlation now is a negative -0.018, which means that darker-skinned black women earn more money than lighter-skinned black women. But of course, the correlation is too weak, not significant at all. We can also see that the independent effect of education level on personal earnings is higher than PPVTw3. The same pattern is displayed in the NLSY97 data. As I explained before, controlling for education is just like controlling for all the effects causing education to vary (e.g., IQ). Stated otherwise, IQ could influence wage in an indirect manner.
Add Health Analysis 3. Now, I look at the relationship between skin color and educational attainment. For black men (N=282), the effect of color does not appear to be trivial. Even when verbal IQ and parental education have been taken into account, skin color is still correlated with education level at 0.159.

")
For black women (N=400), it looks different however. The correlation falls from 0.093 to 0.033. The colorism hypothesis could maintain that black men are simply more discriminated against. After all, they could say that darker skinned men are, more often than not, portrayed as violent and threatening. Why not ? The problem, as I stated earlier, is that skin-tone discrimination, by definition, must be universal. If such discrimination operates at school, it must also operate in the labor market, but this is not the case. That positive correlation (+0.159) among black men appears rather curious, because in the NLSY97 data, darker skinned respondents make more money and have higher education level.

")
To note, this would be useless to study the white sample, because virtually all respondents chose the response “5” (white) in the question measuring the skin color. I also failed to collect a significant number of hispanics in the Add Health public data.
Check for normality and outliers. When there was a significant deviation from normality, this has been mentioned. As shown above, I corrected those deviations when this was necessary. Erceg-Hurn & Mirosevich (2008) talked about some modern robust statistical methods although I haven’t used it here. Now I will discuss the outliers. In fact, for all of the above analyses, if we use the general cutoff of 1 for Cook’s Distance, we would see that none of the cases could have a substantial impact on our results. But if we use the following cutoff, 4/n where n is the sample size, the pattern may appear different.
In the Add Health Analysis 2, I detected three important outliers (cases #416, #837, #1273) for the black male sample with Cook’s D (0.117, 0.039, 0.044) higher than 4/258, or 0.0155. They are removed. And it appears that the effect of skin color remains very weak, but there is a little change regarding the impact of education level, parental education, and PPVTw1 on personal earnings. Overall, the picture hasn’t changed that much. In the same analysis, for black females this time, case #568 has a Cook’s D of 0.021, higher than 4/362, or 0.011. I removed that one. But no impact whatsoever.
In the Add Health Analysis 3, for black males, I detected an important outlier in the Case Summaries table (see Add Health syntax), with a Cook’s Distance of 0.17552, higher than 4/282, or 0.014. So I removed the outlier (case #837 in my SPSS Data Editor). And here is the obtained result. The color-education association is a little bit lower, and surprisingly, the PPVTw1-education association jumped from 0.219 to 0.277.
")
In that case, PPVTw1 (+0.277) becomes really more important than PPVTw3 (+0.173). But in the black female sample, case #836 has a Cook’s D of 0.064 which is higher than 4/400, or 0.010. And as we can see, the effect of PPVTw1 has been diminished while at the same time, the effect of PPVTw3 has increased. And now the difference between PPVTw1 (β = 0.254) and PPVTw3 (β = 0.210) appears trivial.
")
NLSY97 Analysis 1 : blacks. Among the male sample (N=336) the P-P plot shows a pattern that is clearly normal, even if the dots deviate very slightly from the reference line. We can improve this by using again the square root transformation. The color-income correlation has diminished to insignificance (from -0.106 to -0.026). To note, if we do not use the SQRT transformation, the result would appear identical in any case.

")
Among the female sample (N=427) there is a very weak positive correlation between darker skin and income (β = 0.033, p = 0.428) but of course as it is usually the case with income variable, the P-P plot deviates slightly from the normality. I corrected for this by using my sqrtINCOME variable instead of my R_INCOME. And now the positive correlation between darker skin and income is about 0.065.
")
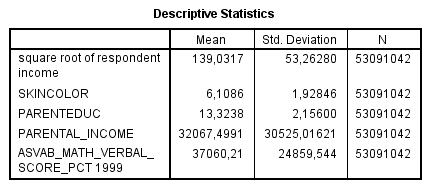
NLSY97 Analysis 1 : hispanics. Again there was a very slight deviation from normality for both males and females. Whether I correct or not for this does not affect the result. Among males (N=311), darker skinned persons earn more money, but again this correlation is really insignificant (β = 0.029).
")
For hispanic women (N=302) the color-income correlation was a negative -0.037 in Model 1 and became a positive 0.052 in Model 3. Here again, darker skinned women make more money.

")
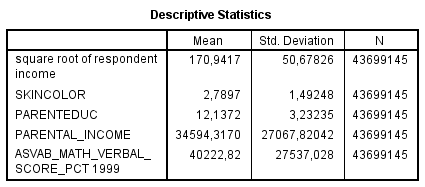
NLSY97 Analysis 1 : whites. The white sample is really interesting, and somewhat curious. For men (N=1057), the negative relationship diminished somewhat but remains negative (β = -0.059, p = 0.052). This clearly contrasts with the hispanic and black samples where darker respondents earn more money.

")
For women (N=921), adding IQ and parental SES does not have any impact on the color-income association. And the correlation remains at -0.093.
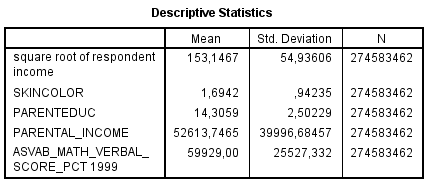
")
NLSY97 Analysis 2 : blacks. Among black males (N=389), we see that after controlling for the effect of parental SES and IQ (model 3), the color-grade correlation becomes positive. As I explained above, this means that darker skinned blacks earn more money. But this is meaningless because of the weakness of the relationship.

")
The same pattern is displayed in the black female sample (N=489). One difference here is that IQ is a better predictor of education level for black women than it is for black men.

")
NLSY97 Analysis 2 : hispanics. Among men (N=339), the color-grade correlation becomes positive, although really weak and non significant (β = 0.032, p = 473).

")
For women (N=348), the negative correlation falls from -0.137 to -0.010. The effect of skin color clearly disappears when parental SES and IQ have been taken into account.

")
NLSY97 Analysis 2 : whites. In the male sample (N=1104), adding parental SES and IQ removes virtually all of the small negative correlation between color and grade.

")
Likewise in the female sample (N=1034), Model 3, the relationship becomes a very small insignificant one, with a negative -0.037. Curiously enough, it looks as if skin tone discrimination is more pronounced in white population than it is in the black population.

")
NLSY97 Analysis 3. Finally, I look at the relationship between skin color and grade level when holding parental SES and IQ constant, while restricting the sample to blacks and whites only. As suspected, the zero-order correlation is negative but, in Model 3, the standardized beta becomes positively associated with the outcome variable, RGRADE.

So, between groups, there is a positive correlation between dark skin and grade level. This is probably because blacks have a higher education level than whites when IQ is held constant. Race and skin color are strongly associated.
Check for normality and outliers. As shown above, I corrected the slight deviations from normality when they were present. So the next question concerns the outliers. If we consider an outlier to be influential only if its Cook’s D is higher than 1, there is no outlier to be found once again. So here again, I use the cutoff of 4/n, and see what is changing after that.
In the NLSY97 Analysis 1, no case displays a Cook value higher than 4/n for the black male sample. But among black women, a serious outlier has been found and removed (#725) in the R0000100 column on SPSS data editor, because his Cook’s D (0.089) was much higher than 4/427, or 0.009. I re-ran the regression after removing it. Previously, the color-income correlation was +0.065 and now it is about +0.087. The effect of parental income has been diminished too (.123 to 0.093). The overall pattern hasn’t changed this much. In NLSY97 Analysis 2, among black men, case #712 has a Cook’s D of 0.015, which is higher than 4/389, or 0.010. But this one has no impact on the result. Among black women, case #681 has a Cook’s D of 0.014, higher than 4/489, or 0.008. No change.
In NLSY97 Analysis 1, for hispanic men, case #432 has a Cook’s D of 0.024, higher than 4/311, or 0.013. But no change after removing it. For hispanic women, there was nothing. In NLSY97 Analysis 2, no individual case displays a high Cook value in the Case Summaries tables for hispanics, males and females.
In NLSY97 Analysis 1, among white men, two outliers have been found (#138 and #563) with a Cook’s D of 0.005 and 0.009, higher than 4/1057, or 0.003. No impact whatsoever. For white women, an outlier (#182) with a Cook’s D of 0.010, higher than 4/921, or 0.004, has been removed. Nothing changed. In NLSY97 Analysis 2, among white men, there was nothing suspicious. Among white women, there were two outliers (#86 and #169) with a Cook’s D of 0.007 and 0.010, higher than 4/1034, or 0.0038. Again, no change.
In summary, the results differ somewhat across surveys but it is not consistent with the cultural hypothesis. The NLSY97 clearly rejects the colorism hypothesis in its entirety, and even predicts the opposite. The Add Health does not support colorism either, to the extent that darker-skinned blacks do not earn less money than the lighter-skinned blacks. If we accept the premise that color-based discrimination should affect all people of both sexes, at every level, colorism is not borne out in those data sets.